Informationen
erfassen und
bearbeiten. Einfache
und effektive Verfahren mittels Webformularen und JavaScript
Vorbemerkung
Bei Internetrecherchen stossen Sie auf ein riesiges Angebot an
Informationen: Datenbankergebnisse, Zeitschriftenlisten zu allen
möglichen Themen usw. Wie kann man auf dieses alles zugreifen,
verarbeiten und mit anderen Informationen und Daten
verknüpfen, um
zusätzliche Informationen zu gewinnen? Der Zugriff auf Daten
entfernter Rechner und deren Verknüpfung ist für
Informationsanbieter im Internet kein so grosses Problem. Sie haben im
allgemeinen direkten Zugriff auf die Daten eines anderen Anbieters,
d.h. vom eigenen Rechner oder Server zu den entfernten Rechnern einer
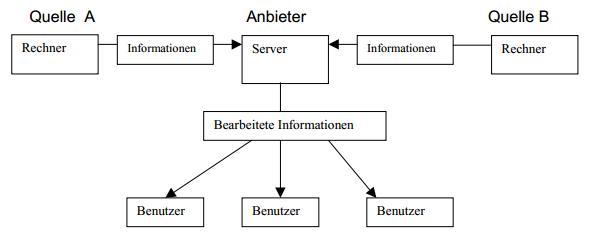
Quelle A oder B, wie das folgende Schema I zeigt.
Schema I: Datenübernahme und Bearbeitung bei Internetanbietern
Der Rechner oder Server des Anbieters erhält Informationen aus
den
verschiedenen Quellen A oder B, bearbeitet und schickt diese an die
einzelnen Computer der Benutzer.
Ihr eigener Computer kann wohl auch als Server fungieren, aber dieser
hat normalerweise keinen direkten Zugriff auf den Rechner eines
Anbieters. Ausserdem: Die Informations- und Datenbanksysteme im
Internet verfügen über sehr leistungsfähige
und schnelle
Rechner, mit denen diese Informationen gespeichert, verarbeitet und
gesendet werden. Mit diesen kann ihr eigener Computer nicht
konkurrieren. Andererseits sind die handelsüblichen Computer
in
den letzten Jahren erstaunlich leistungsfähig geworden, was
die
Schnelligkeit und die Speicherkapazität betrifft.
Es ist also trotzdem und jetzt sogar sehr leicht möglich ist,
auf
diese Informationen direkt zuzugreifen und selbst sehr grosse
Datenmengen in einfachen Formularen zu speichern, was erstaunlich ist
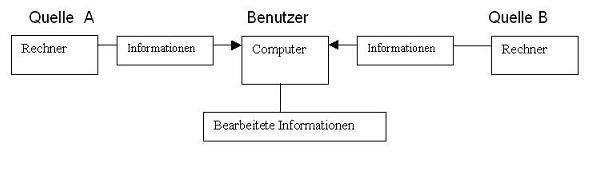
und in dieser Schrift gezeigt werden soll. Schema II zeigt vereinfacht
die Datenübernahme, wie sie mit der hier beschriebenen
Technologie
erfolgt.
Informationssysteme sind im allgemeinen von ausgebildeten Informatikern
mit schwer verständlichen und schwer erlernbaren
Programmiersprachen programmiert. Ausserdem ist der verwendete Code
normalerweise nicht einsehbar. In diesem Bereich waltet, um es etwas
überspitzt auszudrücken, eine elitäre und
esoterische
Atmosphäre.
Gottseidank existiert aber die sehr leicht verständliche und
erlernbare Programmiersprache JavaScript. Vor Jahren las ich
zufällig über sie eine Notiz in einer Zeitung, wo es
hiess,
dass mit JavaScript jetzt quasi eine revolutionäre
Programmiersprache entstanden sei, die es fortan allen erlauben
würde, eigene Programme zu entwickeln, also quasi eine
Demokratisierung des bisher nur für Eingeweihte
zugänglichen
Programmierens.
Das hat mich motiviert, mich einmal mit dieser Programmiersprache zu
beschäftigen. Nachdem ich mir die grundlegenden Kenntnisse
angeeignet hatte, wollte ich die in JavaScript enthaltenen
Möglichkeiten auf die vorhin genannten Informationen im
Internet
anwenden. Man kann diese zwar wie üblich in einer Datei
speichern,
kann aber auf diese mit JavaScript leider nicht zugreifen. JavaScript
besitzt keine Zugriffsberechtigung dafür. Ausserdem
wäre es
umständlich, immer erst Webseiten zu speichern, bevor man auf
ihren Inhalt zugreift. Erst nach einiger Überlegung kam ich,
wohlgemerkt als Programmieranfänger, auf die Idee, die
Informationen durch Copy und Paste in ein Formularfeld
einzufügen.
Als dies auch mit relativ grossen Datenmengen problemlos gelang, war
mir klar, dass damit ein sehr wichtiger Schritt getan war. Wenn die
Informationen erst einmal in einem Formularfeld erfasst sind,
können sie beliebig weiter bearbeitet werden. Sollen sie
allerdings auch gespeichert werden, so ist dies nicht mit reinem
JavaScript, sondern mit der Erweiterung durch dieActive-X-Technologie
möglich, die allerdings auf den IE beschränkt ist.
Auf diese Weise können auch sehr große Datenmengen
sofort in
Formularfeldern erfaßt, bearbeitet und gespeichert werden.
Daß Formularfelder als Datenbanken fungieren und
ausschließlich mit JavaScript und ActiveX operieren
können,
ist bisher noch ungewöhnlich und kaum bekannt. In Hand- und
Lehrbüchern fand ich bisher dafür noch keine
Beispiele.
Bisher wird JavaScript eher für bloße Erweiterungen
von
Webseiten, für Animationen usw. eingesetzt. Als vollwertige
Programmiersprache wird JavaScript nicht ernst genommen, oder
vielleicht sogar als Spielzeug betrachtet. Andererseits hat sich
JavaScript weiter entwickelt. Viele Erweiterungen sind hinzugekommen,
die JavaScript sogar als sehr schwierig erscheinen lassen, die aber in
dieser Schrift nicht berücksichtigt zu werden brauchen, weil
alle
hier besprochenen Anwendungen mit dem ganz einfachen JavaScript
auskommen, das sich auch über Jahre hinweg kaum
geändert hat.
Nach dem Durchlesen dieser Schrift sollten Sie in der Lage sein, selbst
eigene Informations- und Datenbanksysteme mit großen
Datenbeständen zu erstellen, was phänomenal und -
sollte
diese hier beschriebene Technik erst einmal größere
Verbreitung finden - geradezu revolutionär erscheint. Sie
selbst
werden hiermit aufgerufen, dazu beizutragen.
Schema II: Datenübernahme und Bearbeitung mit der hier
dargestellten Technik
Mit Ihrem Computer übernehmen Sie direkt die Informationen der
Quellen A und B. Diese werden in Ihrem Computer gespeichert oder nur
temporär übernommen, nach verschiedenen Kriterien
bearbeitet
und durchsucht.
Die Quelle A sind hierbei im allgemeinen die von verschiedenen
Anbietern (z.B. der EZB) angezeigten Zeitschriftenlisten, die Quelle B
die von Datenbanken angezeigten Suchergebnisse. Diese beiden Quellen
werden durch ein auf Webformularen basierendem JavaScript-Programm
aufgeschlüsselt und die einzelne Elemente miteinander
verknüpft. Vor allem werden die Zeitschriftentitel aus den
Zitaten
erfaßt und mit den Titeln der übernommenen
Zeitschriftenlisten verknüpft. So werden die
zusätzlichen
Informationen gewonnen, die in Datenbankergebnissen nicht oder nur
unzureichend gegeben sind, z.B. die Verfügbarkeit von
Volltexten
und deren Zugänglichkeit. So können auch umfangreiche
Literaturverwaltungssysteme leicht erstellt und diese wiederum mit der
Zeitschriftenverwaltung verbunden werden, so daß ganz
neuartige
Systeme, wie es Contents-Linking II darstellt, entstehen
Daten
mit Copy und Paste erfassen
Daten
und Informationen auf Webseiten oder im Textformat können sehr
einfach durch Copy und Paste in ein
Formular übernommen werden. Sie stehen damit
temporär, d.h.
vorübergehend für eine Bearbeitung zur
Verfügung. Das etwas
umständliche Abspeichern dieser Daten in einer Datei kann
hierbei umgangen werden. Sollen indes diese Daten
anschließend
dauernd zur Verfügung stehen, so kann in einem lokal
installierten Formular dies mittels des ActiveX-Objektes
geschehen. Eine kurzgefaßte Einführung in dessen
Anwendung
finden Sie hier
Dieses
Erfassen von Daten mit Copy und Paste und mit Hilfe eines einfachen
Webformulars ist ein besonders schnelles und effektives
Verfahren, das für viele Aufgabenstellungen der Computerarbeit
anwendbar ist. Natürlich werden dabei evtl. relevante, auf der
Oberfläche einer Webseite nicht sichtbare, d.h. im SourceCode
verborgene Informationen nicht miterfaßt. Man könnte
zwar auch
diesen Code anzeigen lassen und durch Copy und Paste
übernehmen,was aber weniger praktikabel und in diesen
Beispielen auch nicht
relevant ist.
Eine
kurzgefaßte
Einführung in das Programmieren mit JavaScript finden Sie hier
Webformulare
sind
grundlegende Bestandteile dieses Copy und Paste-Verfahrens. Ein
Webformular in seiner einfachsten Form besteht aus mindestens
einem Eingabefeld und einem Schalter, Button genannt. Dieser ist
oft der Schalter zum Abschicken des Formulars, ein sogen.
Submit-Button. Ein einfaches Formular kann aus bloßem
HTML-Code
bestehen ohne JavaScript. Bei den meisten der in den Beispielen
gezeigten Webformularen dagegen wird über Start-Buttons
jeweils
eine entsprechende JavaScript-Funktion ausgelöst, wodurch die
in
das Eingabefeld eingefügten oder eingegebenen Werte, Texte,
Daten usw. bearbeitet werden, wie das folgende Beispiel zeigt.
Fügen
Sie diese Liste
vollständig per Copy und Paste in das obige Eingabefeld ein
und
klicken Sie auf den Start-Button.
Die
Alert-Anzeige stellt
die Liste mit allen Zeilenumbrüchen dar. In der
anschließend
unformatiert ausgeschriebenen Darstellung werden die
Zeilenumbrüche durch Sternchen ersetzt. Die einzelnen Treffer
sind durch 3 Sternchen von einander getrennt, die einzelnen Teile
innerhalb eines Treffers durch 1 Sternchen. Dadurch bleibt die
Struktur der Liste für die weitere Bearbeitung
erfaßbar, ein
sehr wichtiger Umstand für diese Art von Datenerfassung.
Der
HTML-Quellcode für
das oben verwendete einfache Webformular mit einem mehrzeiligen
Eingabefeld und einem Startbutton sieht in vereinfachter, aber
funktionsfähiger Schreibweise so aus
Innerhalb
dieses Codes ist
der Eventhandler onclick bei
der Definition des Buttons eingefügt. Durch das Klicken auf
diesen Button wird über die frei gewählte
Funktionsbezeichnung starte()
das JavaScript-Programm
gestartet.
Der
JavaScript-Quellcode
für das 1. Beispiel, ebenfalls in etwas vereinfachter
Schreibweise
Beachten
Sie, daß der
hier angegebene JavaScript-Code sich innerhalb des oben
angegebenen HTML-Codes, d.h. zwischen <html>
und </html>
befindet und mit diesem zusammen den Quellcode für dieses
Formular bildet!
Das
in einem Webformular
enthaltene mehrzeilige Eingabefeld ist im Gegensatz zu einem
einzeiligen Eingabefeld fähig, auch eine große
Datenmenge von
mehreren hundert KB auf einmal aufzunehmen, jedenfalls mit dem
IE, der in dieser und auch in anderer Hinsicht anderen Browsern
vorzuziehen ist. Diese Tatsache, die manchen verblüffen mag,
kann man ausnutzen, um die im Internet angezeigten Trefferlisten
von Datenbanken oder Listen von Zeitschriften, Zitaten, Texten
usw. zu erfassen und zu bearbeiten. Auch im Textformat
vorliegende Dateien von Aufsätzen, ja ganze Bücher
können auf
diese Weise erfaßt, durchsucht, verändert werden,
z.B. können
die für ein Register relevanten Begriffe erfaßt und
alphabetisch geordnet werden, das Vorkommen von bestimmten
Wörtern kann untersucht, eine Abkürzungsliste
erstellt werden
usw.