4 Datenbanksysteme
Das Prinzip einer einfachen Datenbank wurde bereits in Informationen II erläutert. Datenbanksysteme bestehen aus der eigentlichen Datenbank, der Software für die Verwaltung, Bearbeitung und das Durchsuchen der Datenbank nach verschiedenen Kriterien sowie dem Formular mit den verschiedenen Eingabefeldern, Menüs und Schaltern für den Zugriff auf diese Datenbank. Während das Web- oder Suchformular im Computer des Benutzers geladen wird, befinden sich normalerweise die für die Suchanfrage wesentliche Software und die Datenbank auf dem entfernten Rechner des Anbieters der Datenbank.
Im Unterschied dazu befindet sich das im folgenden dargestellte System mit allen Teilen ausschliesslich im Computer des Benutzers. Nur die integrierten Hyperlinkverbindungen führen zu entfernten Rechnern. In einer lokal installierten Version ist zusätzlich die gesamte integrierte Datenbankverwaltung funktionsfähig, dies allerdings auf den Internet Explorer beschränkt unter Verwendung der ActiveX-Technologie. Ansonsten läuft das System sowohl mit Firefox als auch mit dem IE.
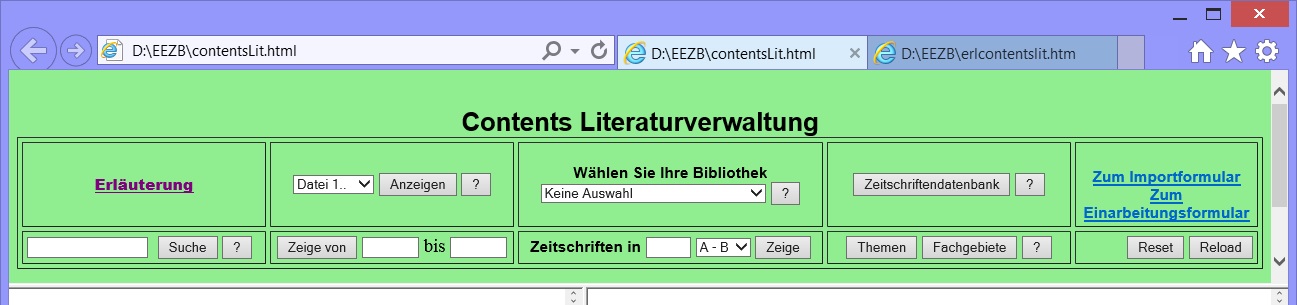
4.1 Contents Literaturverwaltung
Contents Literaturverwaltung ist
das Beispiel eines komplexen Datenbanksystems. Es vereinigt
Das
Formular ist in verschiedene Felder und Abschnitte aufgeteilt. Im
ersten und dem folgenden Abschnitt können Sie
Aufsätze
suchen und anzeigen lassen. Die Aufsätze sind auf 7 Dateien
verteilt, werden ausserdem in einer dynamisch erstellten Gesamtdatei
von ca. 100000 Einheiten erfasst. Jeweils die ersten 5000
Aufsätze der ausgewählten
Datei werden über
den Schalter Anzeigen angezeigt
mit einem
Hyperlink für das Anzeigen weiterer
Aufsätze der ausgewählten Datei. Alle Such- und
Anzeigeoptionen beziehen sich immer und ausschliesslich auf die aktuell
geladene Datei. Im mittleren Abschnitt können die in einer
Aufsatzdatei
enthaltenen Zeitschriften, im folgenden Abschnitt die in der
Zeitschriftendatenbank enthaltenen Zeitschriften und Themen angzeigt
werden, wobei auch jeweils eine Verknüpfung mit der geladenen
Aufsatzdatei besteht.
Die Dateien dat 1.htm bis dat 7.htm enthalten als
Demonstrationsbeispiele jeweils bis zu 20000 Aufsätze, aus
allen
möglichen Fachgebieten, hauptsächlich in Englisch.
Der Inhalt
aller Dateien ist über den Menüeintrag Gesamtdatei
auswählbar. In einer lokal installierten Version
können
beliebig weitere Dateien hinzugefügt werden. Ebenso
können
die bereits vorhandenen Dateien durch die Importfunktion des Multiplen
Linksystems
beliebig ergänzt werden, wobei eine Datei jedoch nicht mehr
als
etwa 20000 Aufsätze enthalten sollte. Die
Höchstgrenze ist abhängig vom verfügbaren
Speicher und beträgt durchschnittlich etwa 50000
Einheiten. Die Datenbank der Zeitschriftentitel wird
durch das Einarbeitungssystem
erweitert oder aktualisiert.
Die Aufsätze wurden in eine vereinfachte Struktur
übersetzt,
die nicht immer einheitlich ist und auch einige Fehler aufweist, die
zum grossen Teil auf die original erfassten Aufsatznachweise
zurückgehen. Durch Beschränkung auf einwandfrei
strukturierte Formate könnten diese Fehler weitgehend
vermieden
werden.
Ein Aufsatznachweis wird in folgender Struktur erfasst:
>2012 z=Proc Natl Acad Sci U S A*Exploring the proton pump and
exit
pathway for pumped protons in cytochrome ba3*from Thermus
thermophilus*Chang HY Choi SK Vakkasoglu AS Chen Y Hemp J Fee JA Gennis
RB*2012 Apr 3;109(14):5259-64.*Sw:
Abgrenzung durch >, es folgen Jahresangabe, Zeitschriftenangabe
eingeleitet durch z=, dann die einzelnen durch Sternchen getrennten
Teile Zeitschriftentitel, Sachtitel, Verfasser, Erscheinungsdaten, am
Ende Sw:, hinter dem ein Schlagwort folgen kann.
4.2
Aufbau und Arbeitsweise
Contents Literaturverwaltung ist ein aus 11 Dateien bestehendes
Framesystem. Die übergeordnete Datei ist contentsLit.htm mit
folgendem Quellcode:
<frameset rows="32%,65%,3%">Die untergeordneten Dateien sind: oben.htm, fenster1.htm; fenster2.htm, dat1.htm bis dat7.htm, ISI_G.htm
<frame src="oben.htm" name=oben>
<frameset cols="45%,55%">
<frame src="fenster2.htm" name="links">
<frame src="fenster1.htm" name="rechts">
</frameset>
<frameset cols="10%,10%,10%,10%,10%,10%,10%,30%">
<frame src="dat1.htm" name="untenL1">
<frame src="dat2.htm" name="untenL2">
<frame src="dat3.htm" name="untenL3">
<frame src="dat4.htm" name="untenL4">
<frame src="dat5.htm" name="untenL5">
<frame src="dat6.htm" name="untenL6">
<frame src="dat7.htm" name="untenL7">
<frame src="ISI_G.htm" name="untenR">
</frameset>
</frameset>
</html>
Die Aktualisierung oder Ergänzung der Zeitschriftendatei durch
neue Titel oder Bestandsnachweise geschieht durch das
Einarbeitungsformular
Einheitliche Datenübernahme aus unterschiedlichen Formaten
Stellen Sie sich ein Webformular vor, in das Sie die Suchergebnisse verschiedener Datenbanken hineinkopieren und das diese ganz unterschiedlichen Zitate in einem einheitlichen Standardformat ausschreiben soll. Nehmen Sie ausserdem an, dass Sie die von der betreffenden Datenbank auf einer Webseite angezeigten Zitate nicht säuberlich von dem übrigen Kontext der Webseite trennen, sondern die gesamte Webseite vollständig kopieren und in das Webformular einfügen. Das kann nicht funktionieren, werden Sie vielleicht mit Recht sagen, vor allem wenn Sie gewohnt sind, nur mit weitgehend strukturierten - möglichst noch mit Metadaten ergänzten - Daten umzugehen. Es war auch für mich verblüffend, dass es möglich sein kann, die verwirrend unterschiedlich angezeigten Suchergebnisse jeweils in dasselbe einheitliche Format zu übertragen.
Der Vorgang in schematischer Darstellung:
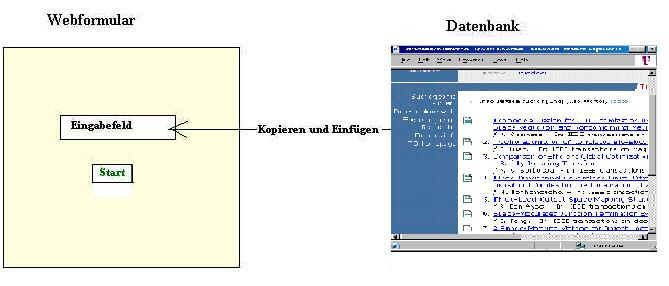
Das Ausgabeformular für die einheitliche Datenübernahme
Starten
Sie das Formular

die
Erläuterung
![]()
Suchergebnisse folgender Datenbanken können eingearbeitet werden:
Für jede Datenbank wird eine schematisierte Codezeile ta verwendet. Bei einigen Datenbanken wird zwischen IE und Firefox unterschieden, z.B. bei JADE ist diese Zeile für den IE:
ta="pv=1>ps=2>pz=3>pe=4>v1=^>s1=\\.|-\\s-|^>z1=\\*In:>e1=\\s\\d+>e2=";
Dazu kommt der Code tr für die Trennung der Zitate:
tr="\\*\\d+";
Je nach ausgewählter Datenbank wird der entsprechende Code in einem einheitlichen Programmteil bearbeitet, auf die eingegebenen Suchergebnisse + Kontext angewandt, und die Zitate schliesslich in den verschiedenen Ausgabeformaten ausgeschrieben. Hier interssiert vor allem das Contents-Link-Format, das besonders vereinfacht ausgeschrieben wird:
>ze=.......(Zeitschrift) *........(Verfasser) *.....(Sachtitel).*......(Erscheinungsvermerk)
.>z=ECOTOXICOLOGY*Oehlmann Jorg 1; Di Benedetto Patrizia 1; Tillmann Michaela 2; Duft Martina 1; Oetken Matthias 1; Schulte-Oehlmann Ulrike 1 *Endocrine disruption in prosobranch molluscs Evidence and ecological relevance.*. 16(1):29-43 February 2007
Die so ausgeschriebenen Zitate sind für Contents-Linking unmittelbar zu verwenden. Sie werden automatisch der Datenbank hinzugefügt.
Die o.g. Codezeilen wurden durch
Allgemeines
Datenübernahmeformular
![]() ermitelt.
ermitelt.
Dieses sehr wichtige Formular dient dazu, aus den unterschiedlichen Formaten von Datenbanken die relevanten Daten zu entnehmen - unabhängig von Metadaten und Standardformaten. Mit einer anschliessenden Bearbeitung lässt sich die Ausgabe der Daten in einem standardisierten Format oder die Übergabe der Daten an ein Such- und Verknüpfungssystem, an ein Linksystem oder eine Literaturverwaltung realisieren. Es handelt es sich also hier um eine wesentliche Basisfunktion sowohl für die Literaturverwaltung im allgemeinen als auch für Linkresolver oder Linksysteme.
Das Formular für die Datenübernahme enthält ein Schema mit einer Anzahl von Feldern. Mit diesem Schema wird ein vorliegendes Format analysiert.
Auf
der Startseite des
Multiplen Linksystems ![]() geben Sie in das Eingabefeld ein einzelnes,
durch mehrere Zeilen strukturiertes Zitat durch Copy und Paste
ein. Durch die Wahl von Neue
Datenbank im
Auswahlmenü öffnen Sie das
Datenübernahmeformular. Siehe dazu
die Erläuterung
geben Sie in das Eingabefeld ein einzelnes,
durch mehrere Zeilen strukturiertes Zitat durch Copy und Paste
ein. Durch die Wahl von Neue
Datenbank im
Auswahlmenü öffnen Sie das
Datenübernahmeformular. Siehe dazu
die Erläuterung ![]()
4.3 ASEZA-Datenbank (entspricht im wesentlichen der Nachfolgeversion Contents-Linking I )
Dieses Datenbank- und Informationssystem ist ein wesentlicher Teil des Multisuchsystems E-Connect. Es kann in der gleichen Weise wie z.B. die EZB verwendet werden, d.h. für die Suche und Anzeige von elektronischen Zeitschriften.
Worin unterscheidet sich dieses System von der EZB? Während die EZB im wesentlichen ein Anzeigesystem ist, die dem Titel nach bekannte elektronische Zeitschriften oder die die Titel eines ganzen ausgewählten Fachgebietes anzeigt, ist dieses System auch ein wirkliches Suchsystem für die Suche nach Zeitschriften, die nicht dem Titel nach bekannt sind. Zu diesem Zweck ist in das System eine Fachwörter- und Themensuche integriert und zusätzlich sind die auswählbaren Fachwörter und Themen jeweils in einem Index anzeigbar. Alle über eine Titelsuche angezeigten Titel werden ausserdem mit dem Hinweis auf die zu diesen Titeln ermittelten Themen verknüpft.
Eine besondere Innovation bietet das Suchsystem durch die wechselseitige Verknüpfung der Themen untereinander. So werden Zeitschriften ermittelt, die gleichzeitig 2 verschiedenen Themen entsprechen. So lässt sich z.B. das Thema Frau mit vielen anderen Themen verbinden, die dann entsprechend eine beschränkte Anzahl von Zeitschriften liefern, was für die Suchpraxis erwünscht ist.
Das Suchsystem enthält im wesentlichen denselben Inhalt wie die EZB. Ca. 60000 Titel wurden bisher integriert. Diese Titel sind grösstenteils der EZB entnommen. Sie sind vielfach mit thematischen Angaben ergänzt, die teils der EZB, teils aber auch aus anderen Quellen entnommen wurden. Im Prinzip können die Titel der Datenbank des Suchsystems ebenso wie die thematischen Ergänzungen aus allen möglichen verfügbaren Quellen übernommen werden, etwa aus Bibliotheks-, Verlags- und Institutionslisten, müssen aber in der Schreibweise an die von Google Scholar bevorzugt erfasste Schreibart angepasst werden. Die Übernahme geschieht über ein automatisch arbeitendes Einarbeitungssystem sowohl für die reinen Titel-, Standort- als auch Themenhinweise. Ausser den Titeln und den thematischen Angaben wurde die ISSN hinzugefügt, wenn diese mit dem Einarbeitungssystem ermittelt werden konnte. Die ISSN kann für die interne Verwaltung der Datenbank von Nutzen sein, um z.B. Doppeleintragungen in unterschiedlicher Schreibweise zu vermeiden, sonst sind sie aber ohne Bedeutung, weil alle Verknüpfungen lediglich über den Titel erfolgen.
Die in den beiden Systemen ASEZA und ASLA enthaltenen Standortangaben sowie die Hinweise auf die allgemeine oder zeitlich beschränkte freie Verfügbarkeit werden ausgewertet und die ermittelten Werte entsprechend angezeigt. Bei Bedarf oder Interesse kann jeder lizenzierte Bibliotheksbestand hinzugefügt werden. Zu beachten ist hierbei, dass viele Artikel von Zeitschriften über Google Scholar frei verfügbar sind, auch wenn sie an sich einer Lizenz unterliegen. Die Verknüpfung mit Google Scholar ergibt nicht nur einen schnellen Zugang zu den in einer Zeitschrift enthaltenen Artikeln, sondern auch zusätzlich zu einer grossen Zahl von sonst nicht frei verfügbaren Volltextartikeln. Die Titel dieses Systems sind daher durchweg mit Google Scholar verknüpft, wodurch der direkteste und schnellste Weg zu Volltexten erreicht wird. Ausserdem bestehen auch Verknüpfungen mit Google und der EZB. Weitere Verküpfungen zu ZDB, SFX, EZB-Link, Springer, WorldCat u.a. könnten bei Bedarf leicht hinzugefügt werden.
Die ASEZA-Datenbank ist ein Open Source Projekt. Der Quellcode in Javascript kann in jeder Weise verändert und erweitert werden. Das System kann für die private und öffentliche, nicht aber für die kommerzielle Benutzung angewandt werden.
In das Suchsystem ist das Einarbeitungssystem und das Aktualisierungssystem WriteDat integriert, mit denen die zugrunde liegenden Datenbanken automatisch erweitert und bearbeitet werden können.
Zum Einarbeitungssystem ist ebenfalls eine Erläuterung vorhanden.
Download
Alle Dateien des Such- einschliesslich Einarbeitungssystems in einer älteren Version können Sie hier herunterladen.
Aufbau und Arbeitsweise
Das Suchformular enthält das Formular Forma1 für die Titelsuche sowie für die Themen- und Fachwörter-Suche und erfasst immer auch die Eingabe der Bibliothekskennung im untersten Abschnitt des Formulars.
Forma1 ist mit action=such1.htm ergänzt. Über die beiden Startschalter wird zunächst diese Datei gestartet, die mit der Scriptdatei contents4.js verbunden ist und beim Laden in dieser die Funktion such0() aufruft. Je nach den übermittelten Werten werden danach verschiedene Funktionen aktiviert: such1() für Titelsuche, index() für Fachwörtersuche, such2() für Themensuche, such2a() für Themenverknüpfungssuche.
Dabei entstehen die Adressenzeilen wie z.B. such1.htm?TI=engl+j&bib&l=de für die Titelsuche bzw. such1.htm?TI=&t=mass&bib=&l=de oder such1.htm?Schlag==bioma&b= für die Themensuche.
Mit TI= ist das Eingabefeld für Titel bezeichnet, mit t= das Eingabefeld für Themen und Termini, mit Schlag== das ausgewählte Thema. Diese Bezeichnungen mit folgenden Suchbegriffen (hier z.B. engl und j ) erscheinen automatisch beim Abschicken des Formulars in der Adressenzeile. Ausserdem wird &bib= bzw. &b= für den Bibliotheksstandort angehängt. Wird in das Formularfeld eine Kennung für eine Bibliothek eingegeben, so wird die Adressenzeile mit dieser Kennung ergänzt
Der Quellcode der Scriptdatei contents4.js dient zugleich auch als Quellcode für das Suchsystem Contents-Linking I, das zusätzlich eine Option für die alphabetische Themenanzeige bietet.
Das Suchsystem besteht aus folgenden Dateien: aseza.html, such1.htm, contents4.js
Das Einarbeitungssystem besteht aus folgenden Dateien: einarbB.htm, einarb2b.htm, g_g.htm, Für die Einarbeitung werden zusätzlich such1.txt, und Themen.txt eingesetzt
Das Aktualisierungssystem WriteDat2.htm verwendet ausserdem noch ThemenA.txt (=Themen.txt)
Die Basisdatei für die Bestandsliste des gesamten Systems ist G_G.txt. Diese ist in such1.htm und g_g.htm enthalten.
5. Bestandsliste und Einarbeitungssystem der Zeitschriftenverwaltung
Die Basisdatei ist G_G.txt. Die Zeitschriften werden darin folgendermassen aufgelistet:
>ACTA
ALBARUTHENICA==
>ACTA ALIMENTARIA=01393006
>ACTA AMAZONICA=anim=biol=trop=tropm=tropoe=*FREI 00445967
>ACTA ANAESTHESIOLOGICA BELGICA=med=*FREI 00015164
>ACTA ANAESTHESIOLOGICA ITALICA=med=*FREI 03744965
>ACTA ANAESTHESIOLOGICA
SCANDINAVICA=med=*AA-*BTU-*G-*JE-*RE*SLUB-*UBEN- *BSB- *TUM- 00015172
>ACTA ANAESTHESIOLOGICA TAIWANICA=med=*JE*SLUB
02541319>ACTA ANALYTICA=phil=*FHMA*G 03535150
>ACTA ANATOMICA SINICA=med=
>ACTA ANDINA=med=*FREI
>ACTA ANGIOLOGICA=med=*FREI 1234950X
>ACTA ANTIQUA ACADEMIAE SCIENTIARUM
HUNGARICAE=arch=clas=*JE*SLUB*SULB*UBEN *BSB null
>ACTA APOSTOLICAE SEDIS=law=rel=*FREI
Zeitschriftentitel, Thema bzw. Themen, wenn vorhanden, Standorte, falls vorhanden, evtl. Zeitbeschränkung, ISSN, falls vorhanden
Die
vorliegende Bestandsliste
ist grösstenteils durch Vergleich von EZB-Listen mit einer GesamtISSN-Liste
entstanden. Diese Liste besteht im wesentlichen aus der
Master Journal List von
Thomson Reuters, ergänzt durch einige andere Listen
elektronischer
Zeitschriften, die im Internet frei zugänglich sind.
Inzwischen ist aber
ein grösserer Bestand von EZB-Titeln integriert worden, die
nicht in der GesamtISSN-Liste gefunden wurden und die daher nicht
mit der ISSN ergänzt werden konnten.
Es ist möglich, EZB- oder andere Zeitschriftenlisten zu übernehmen ohne den Vergleich mit diesen Basislisten, also nur mit den aufgelisteten Titeln und ohne ISSN. Im allgemeinen funktionieren in den Systemen vorhandene Verknüpfungen mit der EZB und der ZDB auch ohne ISSN, und die Verknüpfungen mit Google und GoogleScholar sind ohnehin nur über die Titel möglich. Allerdings muss für die Verknüpfung mit Google Scholar die Schreibweise der Titel an die von Google Scholar vorwiegend erfasste Schreibweise so weit wie möglich angeglichen werden.
Der Vergleich von EZB-Listen mit der GesamtIISN-Liste kann über die Datei BearbEZB3.htm (mit der Erläuterungsdatei ErlEZB.htm) getestet werden.
Viele Änderungen an der Bestandsliste können Sie sehr leicht manuell vornehmen: die Datei G_G.txt wird geöffnet. Änderungen durch die Suchen-Ersetzen-Option. Anschliessend speichern. Ausserdem können Änderungen oder Korrekturen mit dem Bearbeitungsprogramm BearbG.htm automatisch erfolgen.
Die Bestandsliste enthält die Titel in
möglichst
einheitlicher Schreibweise. Diese entspricht im wesentlichen der
Schreibweise der Master
Journal List
von Thomson Reuters mit einigen
Änderungen: Überflüssige Zusätze
zum Titel werden
weggelassen, alleSonderzeichen entfernt,
Serienvermerke vereinheitlicht.
Auf Doppelpunkt, Bindestrich oder
Schrägstrich
folgende Zusätze zum Titel werden enfernt:
METABOLISM - CLINICAL AND EXPERIMENTAL
METABOLISM 00260495
BJU INTERNATIONAL : BRITISH J OF UROLOGY
BJU INTERNATIONAL 14644096
ARCHIVE OF APPLIED MECHANICS / INGENIEUR ARCHIV
ARCHIVE OF APPLIED MECHANICS 09391533
In runden und eckigen Klammern Stehendes wird
entfernt:
ACM TRANSACTIONS ON DATABASE SYSTEMS (ACM TODS)
ACM TRANSACTIONS ON DATABASE SYSTEMS 03625915
J OF SYNCHROTRON RADIATION [SYNCHROTRON RADIATION ONLINE]
J OF SYNCHROTRON RADIATION 09090495
Unterreihen werden in den EZB-Listen in sehr
unterschiedlicher
Weise angegeben. SERIES, PART und SECTION werden in beiden Listen
entfernt, in den EZB-Listen außerdem die ergänzende
Angabe
hinter dem Doppelpunkt. Serienhinweise werden normalerweise nur mit
einem Buchstaben oder einer Ziffer angegeben. Beispiele:
PROCEEDINGS ROYAL SOCIETY OF LONDON SERIES A : MATHEMATICAL PHYSICAL
AND ENGINEERING SCIENCES (1996 -)
PROCEEDINGS ROYAL SOCIETY OF LONDON A 13645021
PHYSICA A : STATISTICAL MECHANICS AND ITS APPLICATIONS
PHYSICA A 03784371
PHYSICA STATUS SOLIDI (A) - APPLIED RESEARCH
PHYSICA STATUS SOLIDI A 00318965
J DE PHYSIQUE II
J DE PHYSIQUE 2=1155-4312
Erstellung der neuen Bestandsdateien ISI_G.txt und g_g.htm
Die
vorläufig und probeweise erstellte Bestandsdatei G_G.txt mit
über 70000, z.T. wissenschaftlich weniger
relevanten Titeln
ist als neu anzulegende Basisdatei nicht gut geeignet, zumal darin auch
einige Fehler und Unstimmigkeiten enthalten sind. Stattdessen sollte
man die Master Journal List zu Grunde legen. In der Bearbeitungsdatei
BearbISI_G.htm
wird die Master Journal List mit der vorliegenden Datei G_G.txt vergleichen. Die Datei ISI_G.txt entsteht. Sobald diese durch das Einarbeitungssystem erweitert bzw. aktualisiert wird, wird aus dieser die neue Datei G_G.txt, die nun der Zeitschriftenverwaltung als erweiterbare Bestandsdatei dient.
Schalter
1: aus originaler ISI-Liste
isijournals.txt wird
isijournals2.txt
Schalter
2: Vergleich mit G_G
: ISI_G.txt entsteht,
in fenster1
gefundene Titel mit Ergänzungen, in
fenster2 nichtgefundene Titel,
anschliessend: Datei g_g.htm für die Zeitschriftenverwaltung erstellen bzw. aktualisieren
Korrekturen der Datei IS_G.txt
können
manuell oder über das Bearbeitungsprogramm BearGI.htm erfolgen. Hierbei
die neu entstandene Datei G-FileA.txt öffnen und als
IS_G.txt speichern, anschliessend g_g.htm (s.o.)
erstellen
Problematisch sind Zeitschriftentitel, die hinter den Zeichen
: -
\ . Zusätze zum eigentlichen Titel
enthalten,
gleichlautende Titel vor allem aus einem Wort bestehende, Serientitel
und Titel mit Abkürzungen am Ende.
Beispiele:
>PALLAS: EINE ZEITSCHRIFT FÜR STAATS- UND KRIEGS-KUNST
=PALLAS
>HUAFEI-GONGYE = J OF THE CHEMICAL FERTILIZER INDUSTRY
=HUAFEI-GONGYE
>HYLE - AN INTERNATIONAL J FOR THE PHILOSOPHY OF CHEMISTRY
=HYLE
>ARCHIVE OF APPLIED MECHANICS / INGENIEUR ARCHIV
=ARCHIVE OF APPLIED MECHANICS
In diesen Beispielen werden die hinter den Zeichen : / - . stehenden
Zusätze
weggelassen. Es gibt aber Fälle, wo die hinter diesen Zeichen
stehenden
Ergänzungen wesentliche, d.h. unterscheidende Zusätze
sind und wo diese daher
nicht weggelassen werden können und wo auch Google Scholar
diese nicht weglässt
und ohne Trennzeichen übernimmt:
>ARCHIVES OF DISEASE IN CHILDHOOD / EDUCATION AND
PRACTICE
= ARCHIVES OF DISEASE IN CHILDHOOD EDUCATION AND PRACTICE
>ARCHIVES OF DISEASE IN CHILDHOOD / FETAL AND NEONATAL
= ARCHIVES OF DISEASE IN CHILDHOOD FETAL AND NEONATAL
>JAHRESBERICHT / UMWELTBUNDESAMT
= JAHRESBERICHT UMWELTBUNDESAMT
>CLINICAL MEDICINE: ARTHRITIS AND MUSCULOSKELETAL DISORDERS
=CLINICAL MEDICINE ARTHRITIS AND MUSCULOSKELETAL DISORDERS
>CLINICAL MEDICINE: BLOOD DISORDERS
=CLINICAL MEDICINE BLOOD DISORDERS
>CLINICAL MEDICINE: CASE REPORTS
=CLINICAL MEDICINE CASE REPORTS
>CURRENT MEDICINAL CHEMISTRY. ANTI-CANCER AGENTS
Darüber hinaus werden noch folgende Angleichungen vorgenommen:
In runden und eckigen Klammern Stehendes wird entfernt:
>ACM TRANSACTIONS ON DATABASE SYSTEMS (ACM TODS)
>J OF SYNCHROTRON RADIATION [SYNCHROTRON RADIATION ONLINE]
Serienvermerke werden im allgemeinen ohne Zusätze nach den
aufzählenden
Zeichen oder Buchstaben (I,II..., A, B C ...) abgeschlossen, die
folgenden Zusätze
weggelassen. SERIES, SECTION, PART wird im allgemeinen beibehalten.
Beispiele:
>ENVIRONMENTAL POLLUTION SERIES A: ECOLOGICAL AND
BIOLOGICAL
=ENVIRONMENTAL POLLUTION SERIES A
>ENVIRONMENTAL POLLUTION SERIES B: CHEMICAL AND PHYSICAL
=ENVIRONMENTAL POLLUTION SERIES B
· Übersetzte Titel (z.B. die russischen nach C/C..)
werden entfernt.
· Umlaute (Ä,Ö,Ü) werden
beibehalten, müssen für die Google Scholar-
Verknüpfung allerdings umgewandelt werden, ebenso die anderen
sprachbezogenen Zeichen.
· Der bestimmte Artikel am Anfang oder Ende eines Titels
wird entfernt.
· Kommas und Semikolons werden grundsätzlich
entfernt.
· Bei der Google Scholar-Verknüpfung darf das
&-Zeichen nicht durch UND ersetzt
und das Apstroph-Zeichen (') nicht weggelassen werden, was aber in den
Thomson-Reuters Titeln durchweg geschieht. Beim Vergleich von
isijournals2 mit
G-File durch das Programm BearbISI_G wird dies berücksichtigt
(s.u.) und ebenso im
Einarbeitungssystem:
Einarbeiten von neuen Titeln, Beständen, Themen
Das System kann jede beliebige Liste von untereinander
geschriebenen Zeitschriftentiteln erfassen. Sollen ganze
Webseiten mit Zeitschriftentiteln übernommen weren,
müssen
diese erst durch ein entsprechendes kleines Programm
bearbeitet
werden. Die Anzeigeseiten der EZB können ohne
Vorbereitung
eingegeben und erfasst werden. Dasselbe System dient zur Einarbeiung
von Titeln, Themen und Standorten. Für
themenbezogenen
Titel wird die Themenkennung, bei standortbezogenen Titeln
wird
die Standortkennung eingegeben. Als Ergebnis werden neue Titel, neue
Themen und Standorte hinzugefügt, die ganze Liste aktualisiert
und
sofort automatisch in das Einabeitungsystem und in die
Zeitschriftenverwalung integriert. s.
Erläuterung
Allgemeines zur Codierung
Die Codierung geschieht in möglichst einfacher Schreibweise, so werden die Variablen am Anfang der Funktionen nicht eigens deklariert. Benennungen von Dateien, von Funktionen und den vielen Variablen sind nicht vereinheitlicht, sondern nach und nach der Entwicklung dieses Systems gewählt worden. Innerhalb des gesamten Codes gibt es auch teilweise überflüssige, nicht mehr verwendete Codes.
Verwendete Suchmethoden sind: indexOf, lastIndexOf, search und match. Mehrfach werden Regular Expressions verwendet. Die Suche in der umfangreichen Bestandsliste geschieht vorwiegend, indem die Bestandsliste in ein Array zerlegt wird und die einzelnen Elemente nacheinander mit der IndexOf-Methode abgefragt werden. Eine andere mehrmals verwendete Möglichkeit besteht darin, auf die Bestandsliste als Ganzes die besonders schnelle Match-Methode mit Reg. Exp. anzuwenden und danach den entstandenen Array abzuarbeiten.
Unterschiede der verwendeten Browser: IE verarbeitet grössere Datenmengen besser als Mozilla. Geringe Unterschiede in der Navigation: In Mozilla kein Einfügen über den entsprechenden Button, sondern nur mit der Tastenkombination Strg-V.
Gleichlautende Titel
Gleichlautende Titel stellen ein gewisses Problem dar. Gleichlautende Titel sind meistens mit einem unterschiedlichen Zusatz verbunden, so dass serienähnliche Titel entstehen. Die in der Bestandsliste enthaltenen gleichlautenden Titel können falsche ISSN und falsche fachliche Zutragungen aufweisen, Fehler, die beim Einarbeiten von gleichlautenden Titeln ohne ISSN entstehen. Um dies zu vermeiden, vergleicht das Einarbeitungsprogramm alle eingegebenen Titel mit einer Liste gleichlautender Titel in der Datei such1g.htm (2. Textareafeld).
Eine Liste gleichlautender bzw. serienähnlicher Titel aus der EZBListe gesamtezb2.txt erhält man über BearbEZBSerien.htm
Serientitel
Diese stellen ein weiteres Problem dar, insofern die auf den Serienvermerk (z.B. auf Part A, Part B usw.) folgenden Zusätze weggelassen werden müssen, weil diese von Google Scholar nicht erfasst werden. Zur Überprüfung können mit dem Programm BearbEZBSerien.htm in separaten Fenstern alle in der EZB enthaltenen Titel in Serien angezeigt werden. Eine Liste dieser Serien ist hier vorhanden.
Titel mit hinzugefügten Abkürzungen
Abkürzungen hinter dem vollen Zeitschriftentitel werden im allgemeinen weggelassen, weil sie auch von Google Scholar nicht erfasst werden. Nachträglich können die fälschlich übernommenen Abkürzungen durch ein spezielles Bearbeitungsprogramm entfernt werden, das alle vorhandenen Titel der Bestandsliste mit einer Liste vergleicht, die die in der EZB enthaltenen problematischen Titel (d.h. Titel, hinter denen die Abkürzung ohne trennendes Zeichen folgt) aufführt.
Der JavaScript-Code des
Einarbeitungsprogramms